

In today’s data-driven world, the need for robust and secure data for testing and analysis has never been more critical. This is where synthetic data comes into play. Synthetic data is the artificial creation of data that closely resembles real-world data while excluding personally identifiable information. It offers a plethora of advantages for businesses, making it an increasingly popular choice for various applications.
Advantages of Using Synthetic Data:

Let’s delve deeper into the advantages of harnessing synthetic data:
1. Data privacy: Synthetic data is void of sensitive information, providing a safe testing environment without risking data breaches or privacy violations.
2. Reduced risk of sensitive data leaks: Businesses can eliminate the threat of sensitive data leaks, safeguarding both their reputation and customer trust.
3. Scalability: Synthetic data can be generated in vast quantities, allowing companies to comprehensively test their systems under various conditions and scenarios.
4. Control over data quality: With synthetic data, businesses maintain complete control over the quality and accuracy of the data used for testing and analysis.
5. Availability: Synthetic data is generated on demand, ensuring that companies have access to the data they need precisely when they need it.
6. Edge case testing: Synthetic data enables businesses to simulate rare edge cases and scenarios that may not be present in real-world data.
7. Flexibility and cost-effectiveness: Synthetic data is a cost-effective alternative to real data, allowing businesses to generate more data for less money and with greater flexibility.
In this comprehensive guide, we will explore the various facets of synthetic data generation, including types of synthetic data and best practices for efficient utilization.
Types of Synthetic Data

Structured Data
Structured data, organized in formats such as tables, spreadsheets, and databases, offers a high degree of predictability. Its consistent format simplifies the process of generating synthetic data with characteristics and properties similar to the source data. This makes it ideal for testing the functionality and performance of systems, software, and hardware during development, prototyping, training, and compliance purposes.
However, structured data may not capture the full complexity of real-world data, potentially lacking the intricacies of customer behavior or market trends.
Unstructured Data
Unstructured data, characterized by its lack of a predefined structure or format, is often text-heavy. It encompasses data such as emails, social media posts, audio and video recordings, and images. Unstructured data’s significance in today’s data-driven business environment cannot be overstated.
Unstructured data finds applications in generating synthetic text data for chatbots, sentiment analysis, and synthetic image data for image recognition and deep learning. Yet, ensuring accuracy and consistency in unstructured data can be challenging due to its lack of structure.
Semistructured Data
Semi-structured data occupies a middle ground between structured and unstructured data. It retains elements of both, often represented in formats like XML, JSON, or HTML. Industries such as healthcare, finance, and retail frequently encounter semi-structured data.
In healthcare, electronic health records contain clinical notes, patient history, and lab results, all of which fall under semi-structured data. Similarly, finance may involve transaction data or financial statements, while retail can encompass customer feedback and product descriptions.
Semi-structured data’s versatility allows for more accurate representation of real-world data, but it comes with challenges related to consistency, standardization, and identifying structured and unstructured elements.
Generating High-Quality Synthetic Data

When generating synthetic data, several critical factors come into play:
Data source: The data source used for synthetic data generation should closely resemble the real-world data it seeks to emulate. This ensures that the synthetic data accurately reflects the properties of the actual data.
Data complexity: Consider the complexity of the data being generated, including the number of fields, relationships between fields, and data patterns.
Data variability: Account for data variability, encompassing factors like the range of values for each field and how these values are distributed within each field.
To generate high-quality synthetic data, adhering to best practices is essential:
Defining Rule-Based Generation Logic: Establish explicit and well-defined rules that govern synthetic data generation. These rules should precisely mirror the statistical features and patterns found in real data.
Validating the Data: Data validation ensures that the synthetic data meets the necessary quality criteria. Techniques such as comparing it to the original data or using statistical tests to check for accuracy and consistency are crucial.
Ensuring Data Privacy: Treat synthetic data with the same level of privacy and security as any other data type. Measures like masking or perturbing sensitive fields can be employed to protect personal information.
Synthetic Data Generators

Synthetic data generators, like Datamaker, leverage advanced algorithms to produce synthetic datasets that faithfully replicate real-world data characteristics. Datamaker offers a wide range of data types, including names, surnames, nationalities, emails, addresses, countries, and credit cards. With Datamaker, you can effortlessly generate fake synthetic data that closely resembles real production data—all with just a few clicks. No coding or anonymization techniques are required, making it an efficient and cost-effective solution for generating large volumes of data.
Testing and Validation

The importance of testing and validating synthetic data cannot be overstated. It ensures that the generated data accurately represents real-world data and aids in identifying and correcting errors. Several methods can be employed for testing and validation, including:
Statistical analysis Compare the statistical properties of the synthetic data to real-world data to ensure alignment.
Visual inspection Visually inspect synthetic data to identify discrepancies or anomalies when compared to real-world data.
Application-specific testing Test the synthetic data in different applications or use cases to verify its accuracy and effectiveness.
Testing and validation should be ongoing processes, particularly as data evolves and changes. Regular testing and validation help maintain the accuracy and value of synthetic data to the business.
Applications of Synthetic Data

Synthetic data has a multitude of real-world applications across various industries:
1. Testing and Training Machine Learning Models: Synthetic data allows testing and training without the use of sensitive or personal data.
2. Testing and Improving Software: It can be used to test software functionality, detect and fix software bugs, and create test cases and data.
3. Market Research: Synthetic data can simulate customer behavior and preferences, enabling companies to test new products and marketing strategies without relying on actual customer data.
4. Cybersecurity: It helps identify potential vulnerabilities by generating fake datasets used to test a company’s IT systems’ security.
5. Energy and Utilities: Synthetic data aids in duplicating energy use patterns, grid data, and sensor readings for energy distribution optimization, demand forecasting, and renewable energy integration testing.
Conclusion
In conclusion, the advantages of using synthetic data are profound, and businesses should seriously consider its adoption. Despite potential concerns about accuracy and understanding, the benefits far outweigh the risks.
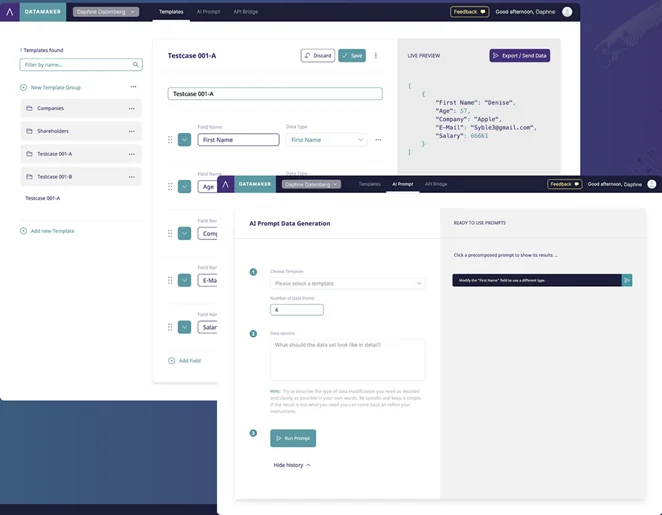
To embark on your journey of synthetic data generation, consider trying Datamaker or booking a live demo here. By embracing synthetic data, your business can access high-quality, diversified, and anonymous data while saving time and money. With the right skills and tools, such as synthetic data generators, synthetic data becomes an invaluable resource across various industries, enabling growth and innovation in a rapidly evolving digital landscape.

