

In today’s fast-paced digital landscape, protecting sensitive information is imperative for businesses across the spectrum. While the significance of data security is widely acknowledged, not all companies take the necessary precautions to fortify their clients’ confidential information.
According to McKinsey, most consumers (87%) say they will not conduct business with a company if they have security concerns. Consumers demand much more transparency from businesses than they may have done two or three years ago.
This article delves into the profound ramifications of neglecting data privacy, employing a real-world case study to underscore the dire consequences and exploring a cutting-edge solution—synthetic data.
The Consequences of Neglecting Data Privacy
One poignant example of the high stakes in data privacy unfolds within the gaming industry. A prominent gaming company embarked on an ambitious mission to overhaul its customer support system. As part of their strategy, they sought to amass sufficient data for rigorous testing.
Faced with an insufficient dataset, the company utilized actual production data gleaned from their database housing intricate details of clients’ payment histories and credit card information. Tragically, a breach in data privacy occurred when the company faltered in its attempts to anonymize and secure the sensitive data adequately.
Lessons from the Data Privacy Fiasco
This fiasco triggered an onslaught of negative repercussions for the gaming company. Frustrated clients, naturally wary of compromised privacy, expressed their discontent. Swift damage control was essential, entailing extensive resource allocation for rectification. The company had to painstakingly reach out to affected customers, launch an internal probe to gauge the extent of the breach and fortify security measures to prevent recurrence.
This sobering incident is an unmistakable reminder of safeguarding confidential information’s importance, especially in domains where customers routinely divulge personal and financial particulars. Furthermore, it underscores the non-negotiable need for businesses to adhere to best practices concerning data security and anonymization meticulously.

Innovating Data Privacy with Synthetic Data
Enter the concept of synthetic data—a potential silver bullet that could have prevented this calamity. Synthetic data involves crafting data sets that mirror the structure and attributes of actual data while preserving the veil of customer anonymity. Had the gaming company opted for synthetic data, they could have seamlessly experimented with new support system functionalities devoid of the specter of compromised confidential information.
Synthetic data could be text, images, video, or tables.
Synthetic text
It has always been challenging to generate realistic synthetic text due to the complexity of languages. However, the emergence of new machine learning models, such as Chat GPT, led to the development of natural language generation systems with exceptional performance.

Synthetic images and videos
Synthetic data can also include video, images, and audio. You generate media with properties sufficiently similar to those of real-world data. This similarity enables the synthetic media to be used as a real data drop-in replacement. For example, thispersondoesnotexist creates fake images of humans that look entirely lifelike. The image below is not of a real people.
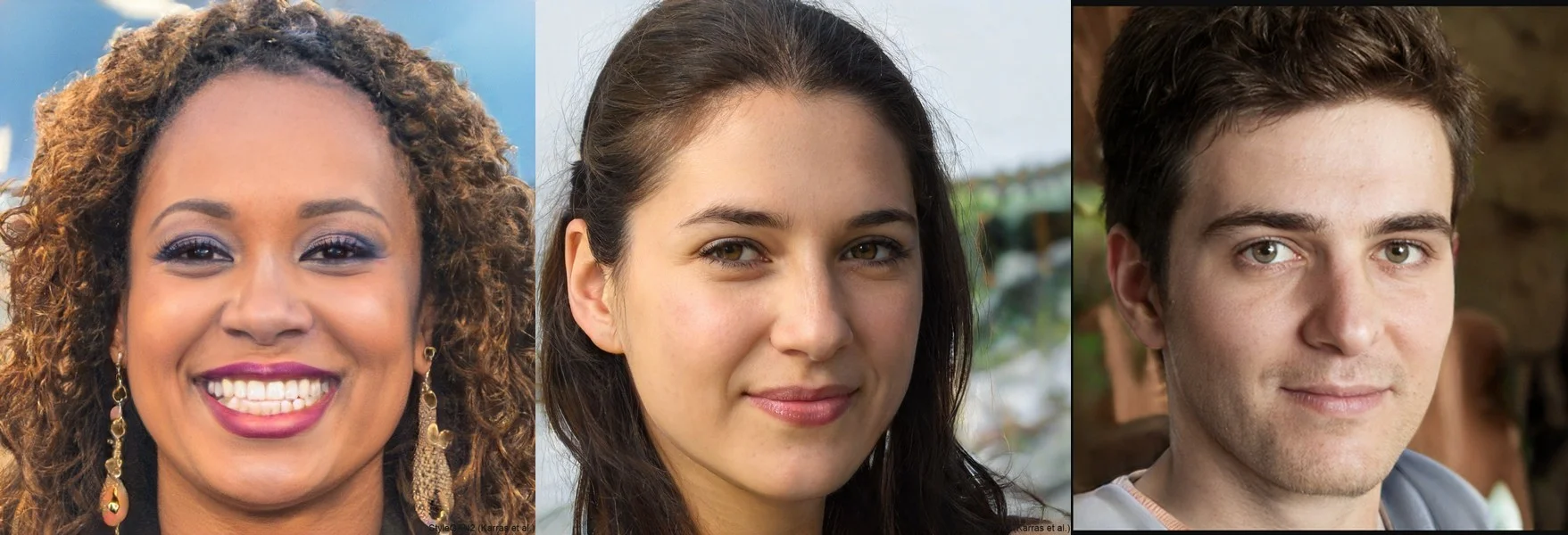
Synthetic tabular data
Tabular synthetic data refers to data generated artificially that resembles tabular data from the real world. This information is organized in rows and columns. It could be anything from a patient database to analytical details about user behavior or financial records.
The Advantages of Synthetic Data
The utilization of synthetic data offers a multitude of advantages vis-à-vis conventional real data usage. Since synthetic data is entirely divorced from actual customer data, the specter of private information exposure is eliminated unequivocally. The cloak of customer anonymity remains intact, forestalling the legal and financial repercussions typically attendant to data breaches. Moreover, generating synthetic data is substantially expedited and simplified compared to the cumbersome and resource-intensive endeavor of collecting, cleansing, and anonymizing real data. This translates to significant savings in terms of time and monetary resources for businesses.
From a business context, over 60% of a data scientist’s time is consumed by the laborious duties of data collection, organization, and cleansing, leaving little time for actual analysis. The challenge grows when handling sensitive medical records and credit card information. The solution resides in synthetic data, which replaces actual data while preserving patterns and characteristics. This eliminates the need to access sensitive data, accelerating the creation of comprehensive analytics and machine learning datasets. This strategy improves decision-making, precision, and insights while maintaining data security.

How Amazon Uses Synthetic Data
The Amazon Alexa team uses synthetic data to train the technology and its natural language understanding. In 2019, Amazon announced three new language versions of Alexa: Hindi, US Spanish, and Brazilian Portuguese.
These, like many new-language launches, addressed the issue of how to bootstrap machine-learning models that understand customer needs without the ability to learn from interactions. The solution, at a high level, is to employ synthetic data. These three locales were the first to take advantage of two new in-house technologies built by the Alexa AI team that produce higher-quality synthetic data more efficiently.
Using synthetic data at Amazon ensures the team can carry out adequate testing without the risk of breaching data privacy rules.

Synthetic Data as a Guardian of Privacy
The case study underscores the gravity of securing sensitive information and the dire consequences that befall those who neglect this duty. The adoption of synthetic data emerges as a potent strategy for businesses aiming to test and innovate without jeopardizing customer privacy. A steadfast commitment to data privacy and security becomes non-negotiable to avert costly mishaps like those at the gaming company in a business landscape increasingly reliant on data-driven insights to refine products and services.
And what better juncture to start with synthetic data exploration than now? Embark on the transformative potential of synthetic data with Datamaker, our fake data generator. Elevate your understanding through a live demo, accessible by booking here, and unlock a realm of innovation fortified by impregnable data privacy.

